




Mini-Gemini: Mining the Potential of Multi-modality Vision Language Models
Yanwei Li, et al.
1. Background & Importance of VLMs
-
1.1. Background:
- Vision Language Models (VLMs) integrate visual and linguistic data to facilitate the understanding and generation of content across multiple modalities. These models synergize the capabilities of both vision and language processing to decode and interpret complex datasets.
-
1.2. Importance:
- VLMs are pivotal in driving advancements in various AI applications, including automated content generation, image description, and interactive AI systems. They play a crucial role in creating technologies that are intuitive and accessible, capable of human-like interactions across diverse data types.
2. Challenges with Mini-Gemini
-
2.1. Challenges:
- Limited resolution in visual understanding impacts the detail and accuracy of image comprehension.
- The quality of datasets used for training VLMs often restricts their learning potential and adaptability.
- Difficulties in integrating visual and textual data into a cohesive model that effectively performs both comprehension and generation tasks.
-
2.2. Objective of Mini-Gemini:
- Enhancing the resolution of visual tokens to capture more detailed and accurate visual information.
- Utilizing high-quality datasets that provide rich and varied training material.
- Developing an integrated approach that boosts the overall capabilities of VLMs, aiming to close the performance gap between current models and more advanced systems like GPT-4 and Gemini.
3. Mini-Gemini Architecture
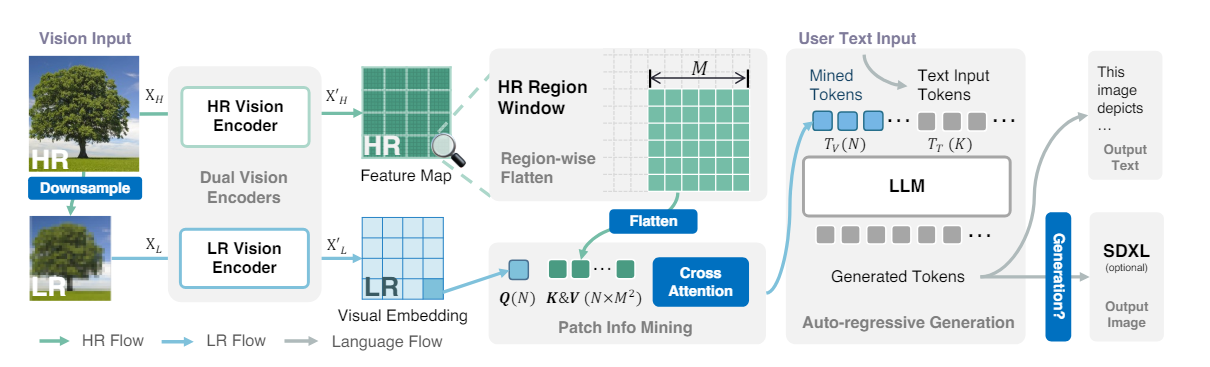
3.1. Image Input and Preprocessing
- High-Resolution Image (XH):
- Input: A high-resolution image denoted as
- Low-Resolution Image Generation (XL):
- Generated via bilinear interpolation from the high-resolution image, resulting in where and are the dimensions of the low-resolution image, ensuring .
3.2. Dual Image Processing Streams
- Low-Resolution (LR) Stream:
- A CLIP-pretrained Visual Transformer (ViT) to encode the low-resolution image, producing visual embeddings , where is the number of visual patches and is the number of feature channels. This maintains the long-range relations among visual patches, supporting subsequent interactions with LLMs (Large Language Models).
- High-Resolution (HR) Stream:
- Employs a CNN-based encoder, LAION-pretrained ConvNeXt for efficient and adaptive processing of the high-resolution image. Generates a high-resolution feature map , where and indicates the pixel-wise feature count within each high-resolution segment.
4. Patch Info Mining
- Purpose: To enhance the potential of Vision Language Models (VLMs) with refined visual tokens while maintaining computational efficiency.
- Process: Combines low-resolution (LR) visual embeddings and high-resolution (HR) feature maps to produce enhanced visual tokens.
4.1. Mechanics of Patch Info Mining
- Inputs:
- LR Visual Embedding serves as the query .
- HR Feature Map split into key and value .
- Operation:
- The patch info mining process is formulated as , where represents a projection layer and MLP stands for a multi-layer perceptron.
- Result:
- This operation synthesizes and refines visual cues to generate enhanced visual tokens , which are well-suited for subsequent processing by Large Language Models (LLMs).
4.2. Efficiency and Detail Enhancement
- Maintains the number of visual tokens for efficiency but enhances detail through strategic retrieval and synthesis.
- Supports visual token extension (up to 5N) to capture more details by processing the original and upscaled images, resulting in a batched input.
4.3. Flexibility in Processing:
- The CNN-based HR vision encoder flexibly handles increased visual token counts during patch info mining.
- Adjustments in sub-regions of are made according to the expanded visual embedding to support higher resolution when needed.
5. Text and Image Generation in Mini-Gemini
5.1. Any-to-Any Inference Capability:
- Mini-Gemini supports both text-only and text-image generation as inputs and outputs, distinguishing it from traditional Vision Language Models (VLMs).
- This flexibility allows for auto-regressive generation using concatenated visual tokens (TV) and text tokens (TT) as inputs to Large Language Models (LLMs).
5.2. Optimizing Language Prompts:
- Unlike other models that focus on bridging the gap between text embeddings and generation models, Mini-Gemini optimizes the use of language prompts to produce context-relevant images using latent diffusion models.
- This strategy is employed in advanced image generation frameworks like DALLE 3 and SORA, which leverage VLM capabilities for superior text conditions in generation tasks.
5.3. High-Quality Data Acquisition:
- For effective cross-modality alignment and instruction fine-tuning, Mini-Gemini utilizes:
- 558K image-caption pairs from the LLaVA-filtered CC3M dataset.
- 695K GPT-4V-responded captions from the ALLaVA dataset.
- Total: 1.2M image captions for pretraining projectors.
- Additional datasets for fine-tuning:
- 643K conversations from LLaVA, excluding 21K TextCaps data.
- 100K QA pairs from ShareGPT4V, and more from LAION-GPT-4V and ALLaVA.
5.4. Instruction-Driven Image Generation:
- Two types of generation tasks are integrated:
- Simple instruction re-caption: Uses descriptive captions to let GPT-4 infer user inputs and generate suitable captions for images.
- In-context prompt generation: Creates prompts from real-world conversations to produce contextually appropriate images.
- Data formatted with
<GEN>trigger and<h>...</h>tags to facilitate image generation processes.
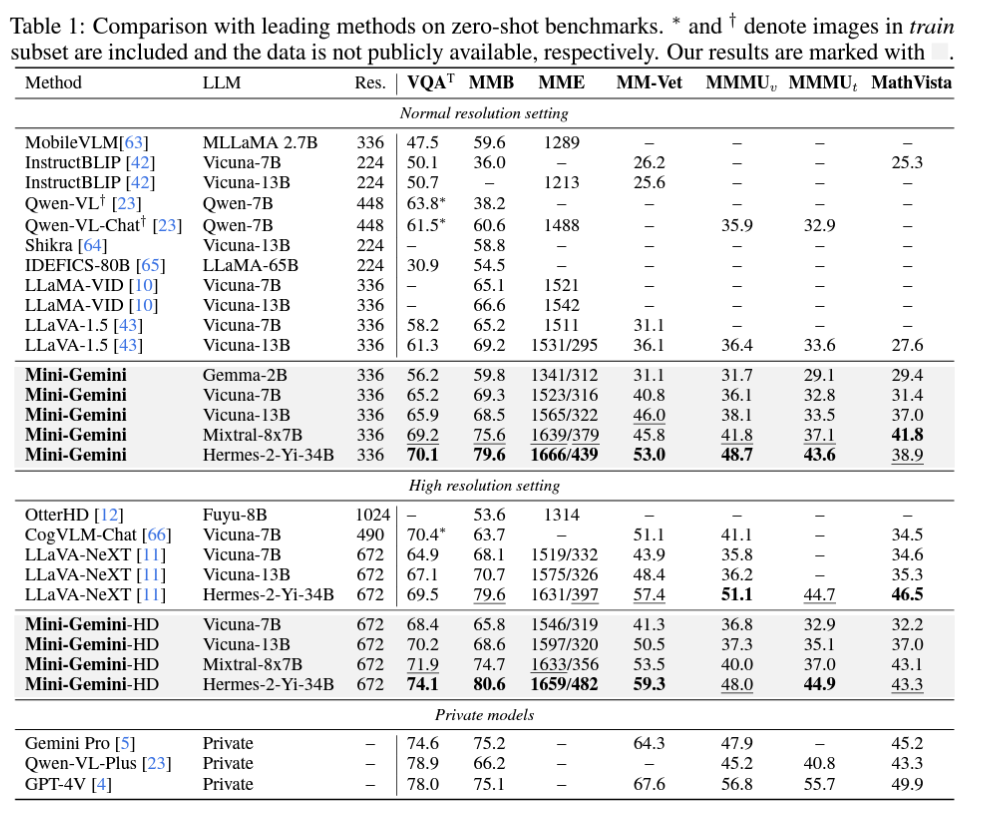
6. Experiments and Results
test1

Original Text
The meme is funny because it humorously combines the concept of a face mask, which is a protective covering worn over the nose and mouth, with the image of Elon Musk, a well-known entrepreneur and public figure. The humor arises from the juxtaposition of a practical item used for health and safety, with the image of a person who is not typically associated with such an item. The meme plays on the idea of a mask in a literal sense, while also making a playful commentary on the person’s identity and public persona. The text “ELON MASK” reinforces the joke by directly referencing the person’s name in conjunction with the mask, creating a pun that is both visually and verbally amusing.
Translation
このミームが面白いのは、フェイスマスク(鼻と口を覆う保護カバー)のコンセプトと、有名な起業家であり公人であるイーロン・マスクのイメージをユーモラスに組み合わせているからだ。このユーモアは、健康と安全のために使われる実用的なアイテムと、そのようなアイテムとは通常結びつかない人物のイメージを並置することから生じている。このミームは、文字通りの意味でマスクのアイデアをもてあそぶと同時に、その人物のアイデンティティと公人としてのペルソナに対する遊び心に満ちたコメントにもなっている。ELON MASK "というテキストは、マスクと連動する人物の名前を直接参照することでジョークを強化し、視覚的にも言語的にも愉快なダジャレを作り出している。

Original Text
The humor in this meme arises from the juxtaposition of the women’s shocked reactions with the cat’s nonchalant demeanor. The text implies that the women were initially alarmed by a cockroach, which is a common source of discomfort for many people. However, the cat’s unbothered expression and the fact that the cockroach is gone create a comedic twist, as the problem has been resolved without the women’s intervention. The cat’s smug expression and the women’s expressions of relief and surprise are exaggerated for comedic effect, playing on the unexpected and humorous resolution of the situation.
Translation
このミームのユーモアは、女性たちの衝撃的な反応と猫の淡々とした態度の並置から生じている。この文章は、女性たちが最初にゴキブリに驚いたことを暗示している。しかし、猫の平然とした表情とゴキブリがいなくなったことで、女性たちの介入なしに問題が解決したという喜劇的な展開が生まれる。猫のドヤ顔と女性たちの安堵と驚きの表情は、コメディー効果を高めるために誇張されており、事態の予想外のユーモラスな解決を演出している。

Original Text
The image captures a moment in a classroom setting, where a teacher is explaining a concept on the blackboard. The teacher, dressed in a white shirt and black pants, is pointing to a diagram that includes a cylinder and a line graph. The students, seated at their desks, are attentively facing the teacher, indicating an ongoing lesson. The classroom environment is typical, with desks arranged in rows and a blackboard at the front. The image does not provide any specific details about the location or the exact content of the lesson, but it clearly depicts a learning scenario.
Translation
この画像は、教師が黒板で概念を説明している教室でのひとコマを捉えたものだ。白いシャツに黒いズボン姿の教師は、円柱と折れ線グラフを含む図を指さしている。机に向かっている生徒たちは、熱心に教師の方を向いており、授業が進行中であることを示している。教室の環境は典型的で、机が一列に並べられ、正面に黒板がある。この画像には、場所や正確な授業内容についての具体的な詳細は示されていないが、学習のシナリオがはっきりと描かれている。

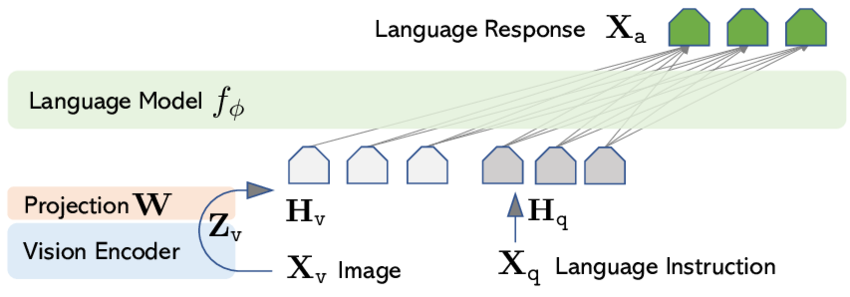
LLaVA Architecture
Comment