




本日のテーマ
- DeiTの概要と使用方法
- モデルをスクリプト化、量子化、最適化して使用するための手順
モデルの性能を比較
DeiT(Data-efficient Image Transformers)とは
-
Image Transformers
自然言語処理で導入されたTransformerモデルを、CVのタスクに応用したもの -
DeiT
画像分類のためにImageNetで学習されたVision Transformerモデル -
従来の画像分類にはCNNが主要モデル
通常では、SOTA結果を達成するために数億枚の画像をトレーニングに使用する必要がある
DeiTはデータと計算リソースに制約のある状況でも、
はるかに少ないデータとリソースでCNNと同等の画像分類性能を発揮できるという
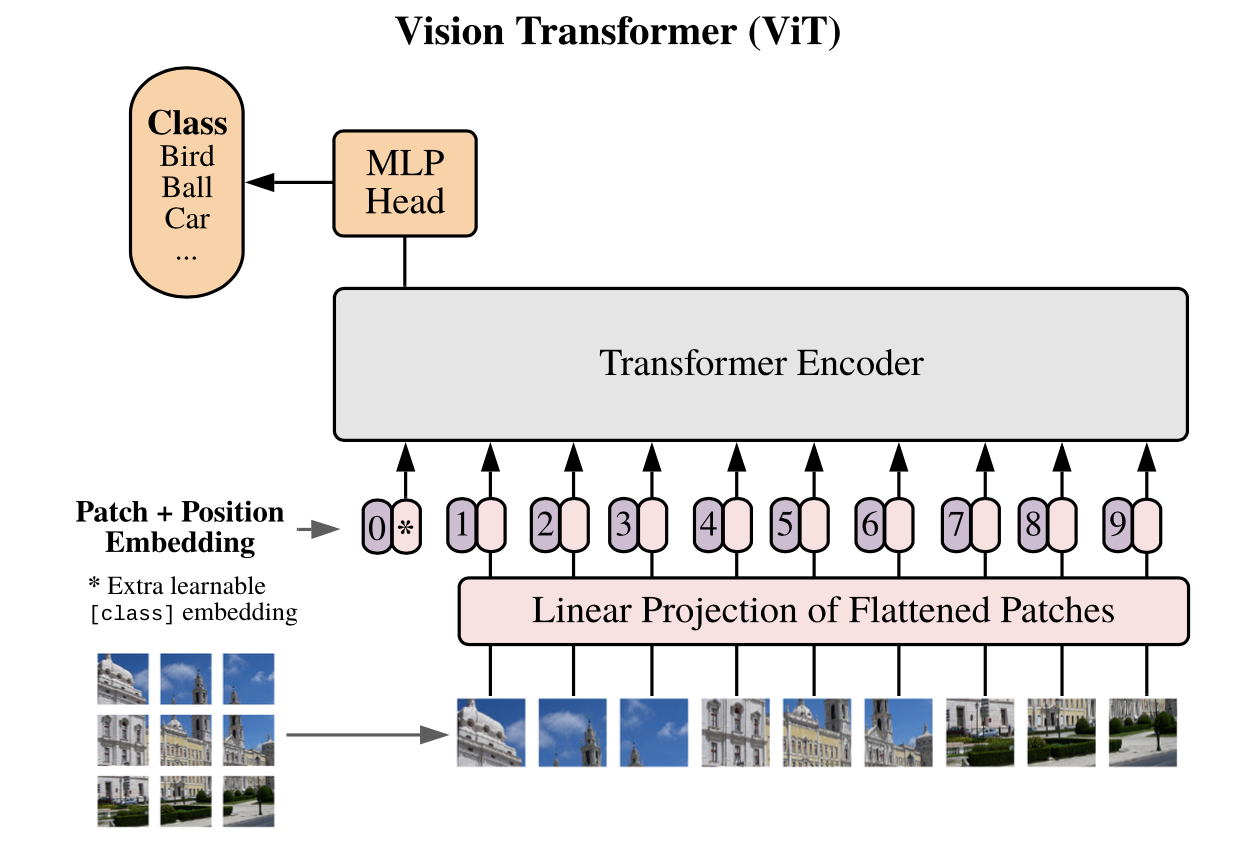
図0

図1
-
データ拡張
Auto-augment, rand-augment, random erasingなど -
TransformerがCNNの出力から学習するNative distillation
Soft distillation: 教師ラベルの分布と生徒モデルの予測分布のKL DivergenceをLossに加える
Hard-label distillation: 教師ラベル、正解ラベルそれぞれに対して生徒モデルの予測分布とのCross Entropy誤差を計算
Distillation token: class tokenと同等のdistillation tokenをpatch tokenとともにTransformerに入力する。distillation tokenに由来するTransformerの出力と教師ラベルから計算したCross Entropy誤差を、class tokenから計算したモデルの予測結果と正解ラベルから計算した通常のCross Entropy誤差に加える。
DeiTにおける画像分類
pip install torch torchvision timm pandas requests
from PIL import Image
import torch
import timm
import requests
import torchvision.transforms as transforms
from timm.data.constants import IMAGENET_DEFAULT_MEAN, IMAGENET_DEFAULT_STD
#(0.485, 0.456, 0.406), (0.229, 0.224, 0.225)
model = torch.hub.load('facebookresearch/deit:main', 'deit_base_patch16_224', pretrained=True)
model.eval()
transform = transforms.Compose([
transforms.Resize(256, interpolation=3),
transforms.CenterCrop(224),
transforms.ToTensor(),
transforms.Normalize(IMAGENET_DEFAULT_MEAN, IMAGENET_DEFAULT_STD),
])
img = Image.open(requests.get("https://raw.githubusercontent.com/pytorch/ios-demo-app/master/HelloWorld/HelloWorld/HelloWorld/image.png", stream=True).raw)
img = transform(img)[None,]
out = model(img)
clsidx = torch.argmax(out)
print(clsidx.item())
#出力
#clsidx.item() = 269
#「timber wolf, grey wolf, gray wolf, Canis lupus」

図2
DeiTのスクリプト化
モバイルでモデルを使用するために、
まずモデルをスクリプト化する必要がある
以下のコードを実行し、
先ほど使用したDeiTモデルをモバイルで実行できるTorchScript形式に変換
model = torch.hub.load('facebookresearch/deit:main', 'deit_base_patch16_224', pretrained=True)
model.eval()
scripted_model = torch.jit.script(model)
scripted_model.save("fbdeit_scripted.pt")
これにより、
スクリプト化されたモデルファイルfbdeit_scripted.ptが作られる
サイズは約346MB
DeiTの量子化
モデルの学習済みモデルサイズを大幅に削減しながら推論精度をほぼ同じに保つために
モデルに量子化を適用することができる
DeiTで使用されるTransformerモデルのおかげで、
LSTMやTransformerモデルには動的量子化が最適
以下のコードを実行します。
backend = "x86"
# サーバー推論では 'x86'
#(古い 'fbgemm' も使用できますが、'x86' が推奨)
#モバイル推論用は「qnnpack」
model.qconfig = torch.quantization.get_default_qconfig(backend)
torch.backends.quantized.engine = backend
quantized_model = torch.quantization.quantize_dynamic(model, qconfig_spec={torch.nn.Linear}, dtype=torch.qint8)
#Linearだけint8へ量子化
scripted_quantized_model = torch.jit.script(quantized_model)
scripted_quantized_model.save("fbdeit_scripted_quantized.pt")
これにより、
スクリプト・量子化されたモデルfbdeit_scripted_quantized.ptが生成される
サイズは約89MBであり、非量子化モデルサイズの26%
スクリプト化および量子化されたモデルを使用して同じ推論結果を生成できる。
out = scripted_quantized_model(img)
clsidx = torch.argmax(out)
print(clsidx.item())
# 同じ結果の269が表示されるはず
DeiTの最適化
モバイルで量子化およびスクリプト化されたモデルを使用する前に、最適化を行う必要がある
from torch.utils.mobile_optimizer import optimize_for_mobile
optimized_scripted_quantized_model = optimize_for_mobile(scripted_quantized_model)
optimized_scripted_quantized_model.save("fbdeit_optimized_scripted_quantized.pt")
生成されたfbdeit_optimized_scripted_quantized.ptファイルのサイズは、
最適化されていないモデルとほぼ同じで
推論結果は変らない
out = optimized_scripted_quantized_model(img)
clsidx = torch.argmax(out)
print(clsidx.item())
# 269が表示されるはず
Liteインタプリタの使用
モデルサイズの削減とLiteインタプリタの推論高速化がどの程度効果があるかを確認するため
モデルのLiteバージョンを作成する
optimized_scripted_quantized_model._save_for_lite_interpreter("fbdeit_optimized_scripted_quantized_lite.ptl")
ptl = torch.jit.load("fbdeit_optimized_scripted_quantized_lite.ptl")
Liteモデルのサイズは非Liteバージョンとほぼ同じだが、
モバイルでLiteバージョンを実行すると推論速度が向上することが期待される
推論速度の比較
元のモデル・スクリプト化モデル・量子化&スクリプト化モデル・最適化された量子化&スクリプト化モデル
の4つのモデルの推論速度の違いを確認する
with torch.autograd.profiler.profile(use_cuda=False) as prof1:
out = model(img)
with torch.autograd.profiler.profile(use_cuda=False) as prof2:
out = scripted_model(img)
with torch.autograd.profiler.profile(use_cuda=False) as prof3:
out = scripted_quantized_model(img)
with torch.autograd.profiler.profile(use_cuda=False) as prof4:
out = optimized_scripted_quantized_model(img)
with torch.autograd.profiler.profile(use_cuda=False) as prof5:
out = ptl(img)
print("original model: {:.2f}ms".format(prof1.self_cpu_time_total/1000))
print("scripted model: {:.2f}ms".format(prof2.self_cpu_time_total/1000))
print("scripted & quantized model: {:.2f}ms".format(prof3.self_cpu_time_total/1000))
print("scripted & quantized & optimized model: {:.2f}ms".format(prof4.self_cpu_time_total/1000))
print("lite model: {:.2f}ms".format(prof5.self_cpu_time_total/1000))
結果は以下のようになる
original model: 581.69ms
scripted model: 694.97ms
scripted & quantized model: 421.52ms
scripted & quantized & optimized model: 397.82ms
lite model: 385.06ms
元のモデルに対する各モデルの推論時間と削減率をまとめた結果は次の通り
Model Inference Time Reduction
0 original model 581.69ms 0%
1 scripted model 694.97ms -19.48%
2 scripted & quantized model 421.52ms 27.53%
3 scripted & quantized & optimized model 397.82ms 31.61%
4 lite model 385.06ms 33.80%
以前転移学習の勉強会で使ったモデルで試す
https://colab.research.google.com/drive/19xyT3R3ztXW7T60FrQCviYXoGn52BEFm?usp=sharing
まとめ
スクリプト化の利点
-
パフォーマンス向上:
スクリプト化によりモデルの実行グラフが静的に最適化され、高速な推論が可能になる
通常のPython実行時に比べて効率的な計算が行われる -
プラットフォーム非依存:
スクリプト化されたモデルは、Python実行環境に依存しない形式で保存される
異なるプラットフォームや環境での利用が容易に
#include <torch/script.h>
int main()
{
// torch::jit::script::Module 型で module 変数の定義
torch::jit::script::Module module;
// 変換した学習済みモデルの読み込み
module = torch::jit::load("model to path/traced_model.pt");
// モデルへのサンプル入力テンソル
torch::Tensor input = torch::ones({1, 3, 256, 256}).to("cuda");
// 推論と同時に出力結果を変数に格納
auto elements = module.forward(input).toTuple() -> elements();
// 出力結果
auto output = elements[0].toTensor();
return 0;
}
- モデル保護:
スクリプト化により、モデルのソースコードが非公開になり
実行グラフとして表現されたモデルの内部の詳細やアルゴリズムが隠蔽される
量子化
- CPU環境の効率向上
- モバイル端末デプロイメント
- FCとLSTMしか使えない
Comment